





An update on the Scholars on Twitter dataset
In 2022, we published a dataset of Scholars on Twitter. This blog post introduces an update to this dataset and discusses some of the challenges with our data providers: Twitter, Crossref, and OpenAlex. These challenges made the original dataset and process obsolete and this update necessary.
Introduction
On August 21, 2022, we made available the first version of our dataset of scholars on Twitter created with two open data sources: Crossref Event Data and OpenAlex. We reported on the dataset’s creation and validation in a data paper published in Quantitative Science Studies (Mongeon et al., 2023). Soon after the publication of the dataset, the procedure and the accompanying paper, two unexpected changes occurred with the source data providers, Crossref and OpenAlex. One made our process impossible to repeat in the future, and the second made the dataset to a large extent less usable. This short blog post describes those two issues and their impact on the reproducibility and usability of the dataset, and how we mitigated those issues to produce a new, usable version of the dataset, that is now available on Zenodo.
Reproducibility issue - Musk buys Twitter
One of the consequences of Elon Musk buying Twitter in 2022 was an increased barrier to Twitter data access. Two weeks after Crossref’s first announcement, on February 1st, 2023, to abandon the collection of Twitter data, a follow-up post confirmed it as stated below:
“Since 22 February 2023, we no longer have access to the Twitter API to gather events for Twitter. Tweets will be available until the end of February, however we are required to remove all data we have collected from Twitter and will begin to do so in the coming days.“
What this meant for our dataset is that we were no longer going to be able to use Crossref Event Data to collect information on accounts tweeting scholarly works - one of the two crucial pieces of our process - making dataset updates using the same approach impossible. At the same time it also made it a unique dataset in itself, since with the disappearance of the academic Twitter API, it became virtually impossible to develop similar approaches with the currently available tools.
Usability issue - OpenAlex changes all author IDs
On June 20th, 2023, OpenAlex announced a major update in its author disambiguation system. They then announced its successful implementation on August 11th, 2023. This update introduced a new disambiguation model and a live assignment system for authors and affiliations, necessitating the complete replacement of all previous OpenAlex author IDs with new ones. Although this systemic refresh significantly reduced "author splitting" and improved the integration of ORCID identifiers—resulting in a more accurate count of authors dropping from 127 million to 92 million and a leap in works linked to ORCID from 15% to 41%—it also introduced challenges related to data consistency and traceability. Users who had relied on previous author IDs found themselves facing the need to update their datasets as the old IDs were rendered obsolete and began returning 404 errors.
While bolstering the database's accuracy and user experience, this move rendered our dataset obsolete by invalidating the OpenAlex author IDs that we had paired with Twitter accounts. This illustrates the delicate balance between enhancing data integrity and maintaining continuity for users reliant on the persistence of identifiers and the intricate challenges of advancing open infrastructures for scholarly metadata (Hendricks et al., 2021).
Updating the Scholars on Twitter dataset in light of these changes
The matching process
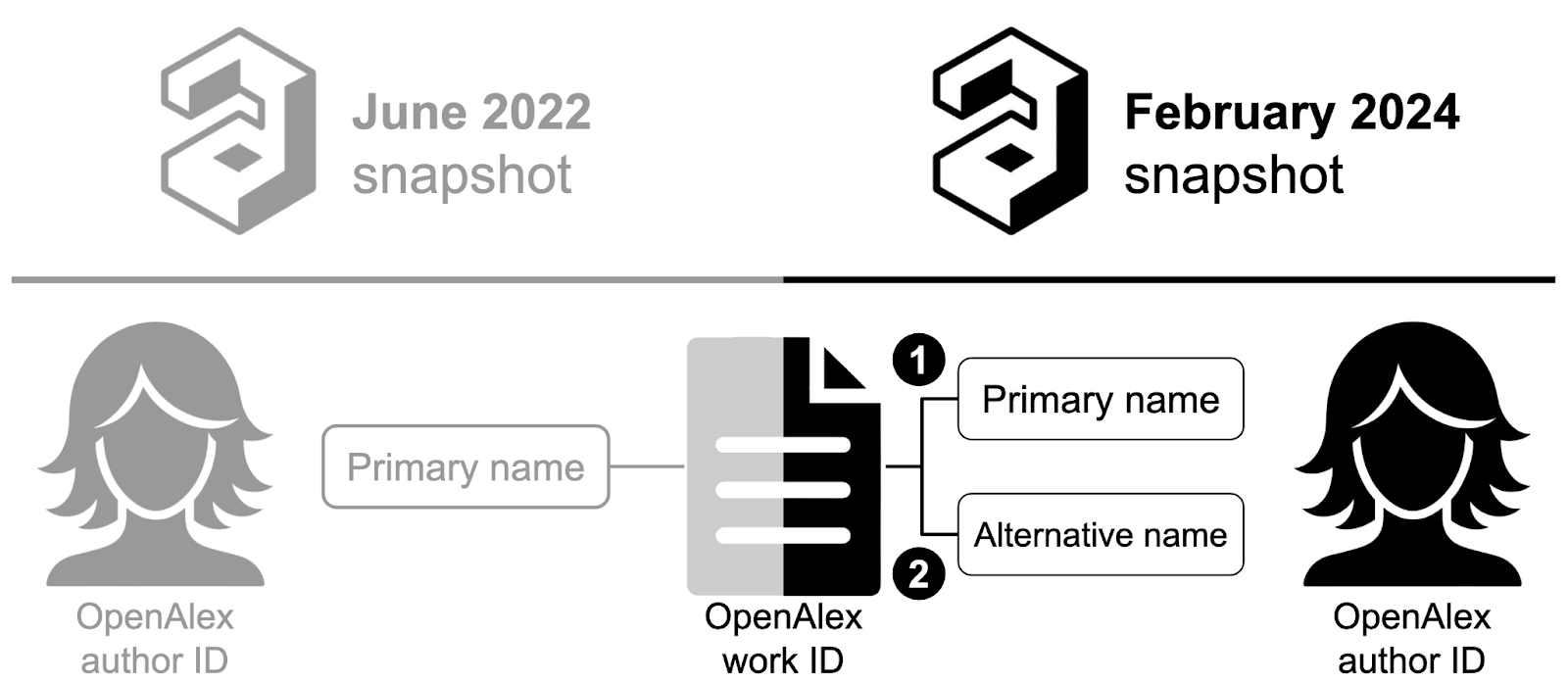
Following the significant update to OpenAlex's author identification system, the Scholars on Twitter dataset, which previously linked Twitter IDs to OpenAlex author IDs, immediately became outdated. This called for a new approach to re-establish these links, as the absence of new Twitter data made it impossible to replicate the original method of matching Twitter profiles with scholarly authors. To navigate this challenge, a bridge was constructed between the June 2022 snapshot of the OpenAlex database—used in the original matching process—and the most recent snapshot from February 2024. We employed the public versions of OpenAlex in Google BigQuery made available at the InSySPo project, in Campinas, Brazil (see an introduction to this system in this open course), and the scripts are available in a GitHub repository. This bridge utilised OpenAlex work IDs and DOIs to match authors in both datasets by their shared publications and identical primary names. When a connection was established between two authors with the same name, the new OpenAlex author ID was assigned to the corresponding Twitter ID. When direct matches based on primary names were not found, an attempt was made to establish connections by matching the names from June 2022 with any corresponding alternative names found in the 2024 dataset. This method ensured continuity of identity through the system update, adapting the strategy to link profiles across the temporal divide created by the database's overhaul.
Announcing the Scholars on Twitter dataset version 2.0
Our method for re-establishing links between author IDs and Twitter profiles has been notably successful, managing to rematch 432,417 (88%) OpenAlex author IDs. This effort successfully restored connections for 388,968 unique Twitter users, which represents 92% of the original dataset. Of these, 375,316 were matched using their primary names, and 57,101 through alternative names. The simplicity and quick execution of this approach led to exceptionally favorable results, with a minimal loss of only 8% of the original Twitter-linked scholarly accounts.
We have republished the dataset in Zenodo and it can be found here. While the dataset still cannot be updated with new Twitter profiles and our original process remains unreproducible, we are happy to bring to the research community an open dataset of 388,968 Twitter accounts linked to OpenAlex author IDs that can be used in the study of the activities of scholars on Twitter and science-social media interactions more generally.
Finally, our case represents a cautionary reminder for open research information systems like OpenAlex, which should work not only to ensure the persistence of their identifiers (for authors, affiliations, journals, works, etc.) but also to support the sustainability of other infrastructures that other communities may build around their open data, like in the case of our dataset or, similarly, the new Open Edition of the Leiden Ranking.
Header image created with GPT-4/Dall-E
DOI: https://doi.org/10.59350/abapf-y4f53 (export/download/cite this blog post)
0 Comments
Add a comment